- 四、研究方法和技术路线
- 五、可行性分析
- 六、本项目创新之处
- 食物数据库
- 配餐体系和评价
- 自动配餐
- 知识图谱构建
- 合理膳食传播和改善
- Computer Vision and Pattern Recognition
- 膳食宝塔
- 食物营养成分查询
- 开源程序
营养信息共享平台建设
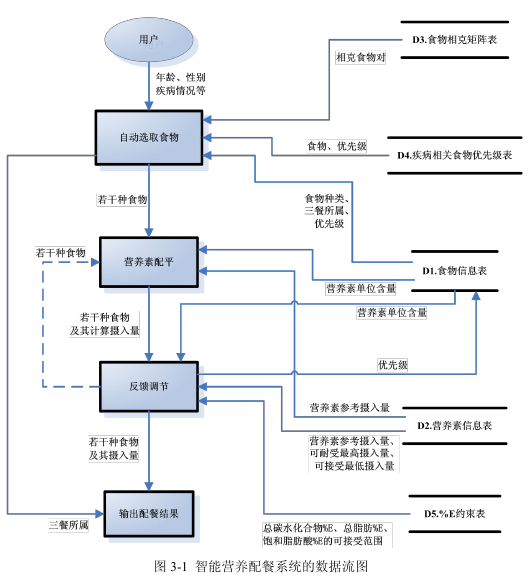
借助食物数据库,研究智能膳食配餐体系和评价标准,研究智能自动配餐技术。应用数字化知识图谱,为我国健康中国合理膳食行动知识体系传播和改善提供多维度信息和技术支撑。
四、研究方法和技术路线
五、可行性分析
六、本项目创新之处
食物数据库
- https://fdc.nal.usda.gov/fdc-app.html
- https://nlc.chinanutri.cn/fq/
- https://github.com/mneedham/bbcgoodfood
- https://www.bbcgoodfood.com/
配餐体系和评价

自动配餐
知识图谱构建
docker run \
--publish=7474:7474 --publish=7687:7687 \
--volume=$HOME/neo4j/data:/data \
-v $HOME/neo4j/plugins:/var/lib/neo4j/plugins \
-v $HOME/neo4j/conf/apoc.conf:/var/lib/neo4j/conf/apoc.conf \
-v -v $HOME/neo4j/import:/var/lib/neo4j/import \
neo4j
apoc.import.file.enabled=true
sudo cp /var/lib/neo4j/labs/apoc-4.3.0.3-core.jar /var/lib/neo4j/plugins/
sudo chown neo4j:neo4j /var/lib/neo4j/plugins/apoc-4.3.0.3-core.jar
sudo systemctl restart neo4j
What’s cooking? Part 1: Importing BBC goodfood information into Neo4j
"97123","Seriously rich chocolate cake","butter"
"97123","Seriously rich chocolate cake","flour"
"97123","Seriously rich chocolate cake","dark chocolate"
"97123","Seriously rich chocolate cake","egg"
"97123","Seriously rich chocolate cake","ground almond"
"97123","Seriously rich chocolate cake","kirsch"
"97123","Seriously rich chocolate cake","salt""caster sugar"
"97123","Seriously rich chocolate cake","cocoa powder"
CREATE INDEX ON:Ingredient(value);
CREATE INDEX ON:Recipe(id);
LOAD CSV FROM "file:///bbcgoodfood.csv" AS line
MERGE (r:Recipe {id:line[0]})
ON CREATE SET r.title= line[1]
MERGE (i:Ingredient {value:line[2]})
CREATE (r)-[:CONTAINS_INGREDIENT]->(i)

:params jsonFile => "file:///stream_all.json";
CALL apoc.load.json($jsonFile) YIELD value
WITH value.page.article.id AS id,
value.page.title AS title
MERGE (r:Recipe {id: id})
SET r.name = title;
CALL apoc.load.json($jsonFile) YIELD value
WITH value.page.article.id AS id,
value.page.recipe.ingredients AS ingredients
MATCH (r:Recipe {id:id})
FOREACH (ingredient IN ingredients |
MERGE (i:Ingredient {name: ingredient})
MERGE (r)-[:CONTAINS_INGREDIENT]->(i)
);
CREATE INDEX ON :Recipe(id);
CREATE INDEX ON :Ingredient(name);
CREATE INDEX ON :Keyword(name);
CREATE INDEX ON :DietType(name);
CREATE INDEX ON :Author(name);
CREATE INDEX ON :Collection(name);
:params jsonFile => "file:///stream_all.json";
CALL apoc.load.json($jsonFile) YIELD value
WITH value.page.article.id AS id,
value.page.title AS title,
value.page.article.description AS description,
value.page.recipe.cooking_time AS cookingTime,
value.page.recipe.prep_time AS preparationTime,
value.page.recipe.skill_level AS skillLevel
MERGE (r:Recipe {id: id})
SET r.cookingTime = cookingTime,
r.preparationTime = preparationTime,
r.name = title,
r.description = description,
r.skillLevel = skillLevel;
CALL apoc.load.json($jsonFile) YIELD value
WITH value.page.article.id AS id,
value.page.article.author AS author
MERGE (a:Author {name: author})
WITH a,id
MATCH (r:Recipe {id:id})
MERGE (a)-[:WROTE]->(r);
CALL apoc.load.json($jsonFile) YIELD value
WITH value.page.article.id AS id,
value.page.recipe.ingredients AS ingredients
MATCH (r:Recipe {id:id})
FOREACH (ingredient IN ingredients |
MERGE (i:Ingredient {name: ingredient})
MERGE (r)-[:CONTAINS_INGREDIENT]->(i)
);
CALL apoc.load.json($jsonFile) YIELD value
WITH value.page.article.id AS id,
value.page.recipe.keywords AS keywords
MATCH (r:Recipe {id:id})
FOREACH (keyword IN keywords |
MERGE (k:Keyword {name: keyword})
MERGE (r)-[:KEYWORD]->(k)
);
CALL apoc.load.json($jsonFile) YIELD value
WITH value.page.article.id AS id,
value.page.recipe.diet_types AS dietTypes
MATCH (r:Recipe {id:id})
FOREACH (dietType IN dietTypes |
MERGE (d:DietType {name: dietType})
MERGE (r)-[:DIET_TYPE]->(d)
);
CALL apoc.load.json($jsonFile) YIELD value
WITH value.page.article.id AS id,
value.page.recipe.collections AS collections
MATCH (r:Recipe {id:id})
FOREACH (collection IN collections |
MERGE (c:Collection {name: collection})
MERGE (r)-[:COLLECTION]->(c)
);
图数据库的查询
有了一些数据,我们可以问一些简单的问题,例如,最常见的成分是什么?
MATCH (i:Ingredient)<-[rel:CONTAINS_INGREDIENT]-(r:Recipe)
RETURN i.name, count(rel) as recipes order by recipes desc

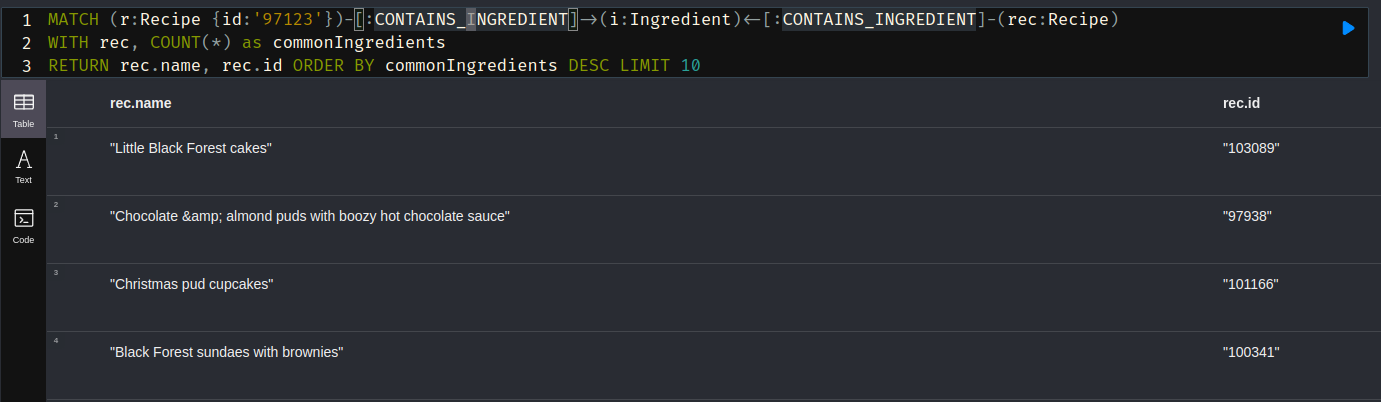
或者,建议一些与巧克力蛋糕类似的其他食谱怎么样?这是一个简单的查询,它将使用几乎相同的成分提出一些推荐食谱:
MATCH (r:Recipe {id:'97123'})-[:CONTAINS_INGREDIENT]->(i:Ingredient)<-[:CONTAINS_INGREDIENT]-(rec:Recipe)
WITH rec, COUNT(*) as commonIngredients
RETURN rec.name, rec.id ORDER BY commonIngredients DESC LIMIT 10
现在我们有了一个丰富而有趣的数据集,可以在图形数据库中进行探索。回到巧克力蛋糕,作者还发表了什么?
MATCH (rec:Recipe)<-[:WROTE]-(a:Author)-[:WROTE]->(r:Recipe {id:'97123'})
RETURN rec.name, rec.id

https://medium.com/neo4j/whats-cooking-part-2-what-can-i-make-with-these-ingredients-7df9dc129993
该查询查找包含辣椒的食谱,然后返回食谱名称及其成分列表:
MATCH (r:Recipe)
WHERE (r)-[:CONTAINS_INGREDIENT]->(:Ingredient {name: "chilli"})
RETURN r.name AS recipe,
[(r)-[:CONTAINS_INGREDIENT]->(i) | i.name]
AS ingredients

但是,如果我们想找到包含多种成分(例如辣椒和虾)的食谱怎么办?一种方法是更新我们的 WHERE 子句以查找包含这些成分的所有食谱:
MATCH (r:Recipe)
WHERE (r)-[:CONTAINS_INGREDIENT]->(:Ingredient {name: "chilli"})
AND (r)-[:CONTAINS_INGREDIENT]->(:Ingredient {name: "prawn"})
RETURN r.name AS recipe,
[(r)-[:CONTAINS_INGREDIENT]->(i) | i.name]
AS ingredients
LIMIT 20

如果我们知道要搜索多少种成分,那么这种方法很有效,但如果我们想搜索动态数量的成分,则效果不太好。要搜索可变数量的成分,我们需要使用all谓词函数。
让我们远离辣椒和虾,这次找到含有鸡蛋、洋葱和牛奶的食谱。然后,我们将按照成分数量升序对生成的食谱进行排序:
:param ingredients => ["egg", "onion", "milk"];
MATCH (r:Recipe)
WHERE all(i in $ingredients WHERE exists(
(r)-[:CONTAINS_INGREDIENT]->(:Ingredient {name: i})))
RETURN r.name AS recipe,
[(r)-[:CONTAINS_INGREDIENT]->(i) | i.name]
AS ingredients
ORDER BY size(ingredients)
LIMIT 20
不幸的是,到目前为止我对大多数菜肴都过敏,所以我想尝试找到一些我可以吃的东西。
我们将添加一个包含过敏原的参数来配合我们的成分参数。
然后,我们可以使用none谓词函数来确保我们不会返回任何包含过敏原的食谱:
:param allergens => ["egg", "milk"];
:param ingredients => ["coconut milk", "rice"];
MATCH (r:Recipe)
WHERE all(i in $ingredients WHERE exists(
(r)-[:CONTAINS_INGREDIENT]->(:Ingredient {name: i})))
AND none(i in $allergens WHERE exists(
(r)-[:CONTAINS_INGREDIENT]->(:Ingredient {name: i})))
RETURN r.name AS recipe,
[(r)-[:CONTAINS_INGREDIENT]->(i) | i.name]
AS ingredients
ORDER BY size(ingredients)
LIMIT 20
合理膳食传播和改善
“在计算机视觉中,食物大多被忽视,因为我们没有进行预测所需的大规模数据集,”麻省理工学院博士后 Yusuf Aytar 说,他与麻省理工学院教授 Antonio Torralba 共同撰写了一篇关于该系统的论文。 “但社交媒体上看似无用的照片实际上可以提供有关健康习惯和饮食偏好的宝贵见解。”
给定一张食品照片,Pic2Recipe 可以识别面粉、鸡蛋和黄油等成分,然后建议一些它确定与数据库中的图像相似的食谱。 (该团队有一个在线演示,人们可以上传自己的食物照片来测试。)
维也纳 MODUL 大学新媒体技术系助理教授 Christoph Trattner 表示:“你可以想象人们用它来跟踪他们的日常营养,或者在餐厅拍摄他们的饭菜,然后知道在家做饭需要什么。”
研究人员还有兴趣将该系统开发为“晚餐助手”,根据饮食偏好和冰箱中的物品清单,该系统可以计算出要煮什么。
“这可能会帮助人们在没有明确的营养信息的情况下弄清楚食物中的成分,”海因斯说。 “例如,如果您知道一道菜中包含哪些成分,但不知道数量,则可以拍照,输入成分,然后运行模型来查找已知数量的类似食谱,然后使用该信息来近似您自己的食谱。一顿饭。”
Computer Vision and Pattern Recognition
-
https://www.amazon.science/blog/using-food-images-to-find-cooking-recipes
-
https://news.mit.edu/2017/artificial-intelligence-suggests-recipes-based-on-food-photos-0720
膳食宝塔
食物营养成分查询
https://www.shiwuchengfen.com/Food/Search
http://yycx.yybq.net/
开源程序
https://github.com/vangelov/calories-in
https://github.com/LuckybugQ/iNutrition
https://github.com/wangtianrui/NutritionMaster
http://pic2recipe.csail.mit.edu/