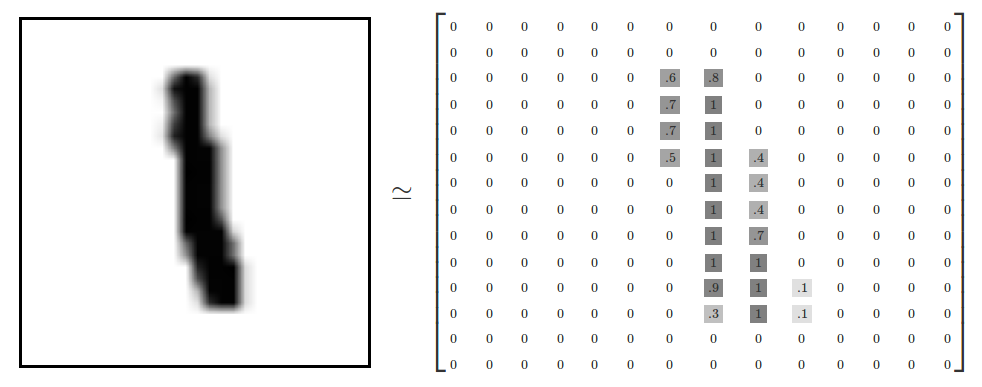
说明
- KNN作为惰性学习方法,训练和测试同时进行
- Classifying with k-Nearest Neighbors
tensorflow实现KNN对手写字的分类
https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/2_BasicModels/nearest_neighbor.py
import tensorflow as tf
import numpy as np
print(tf.__version__)
print(np.__version__)
使用TensorFlow自带的数据集作为测试
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
划分训练集和测试集
Xtrain, Ytrain = mnist.train.next_batch(5000) #从数据集中选取5000个样本作为训练集
Xtest, Ytest = mnist.test.next_batch(200) #从数据集中选取200个样本作为测试集
创建tensorflow结构
# 输入占位符
xtr = tf.placeholder("float", [None, 784])
xte = tf.placeholder("float", [784])
# 计算L1距离
distance = tf.reduce_sum(tf.abs(tf.add(xtr, tf.negative(xte))), reduction_indices=1)
# 获取最小距离的索引
pred = tf.arg_min(distance, 0) # np.argmin(sess.run(distance, feed_dict={xtr: Xtrain, xte: Xtest[i, :]}))
测试模型
# 初始化变量
init = tf.global_variables_initializer()
#分类精确度
accuracy = 0.
# 运行会话,训练模型
with tf.Session() as sess:
# 运行初始化
sess.run(init)
# 遍历测试数据
for i in range(len(Xtest)):
# 获取当前样本的最近邻索引
nn_index = sess.run(pred, feed_dict={xtr: Xtrain, xte: Xtest[i, :]}) #向占位符传入训练数据
# print("Test", i, "Prediction:", Ytrain[nn_index],"True Class:", Ytest[i])
# print(np.argmin(sess.run(distance, feed_dict={xtr: Xtrain, xte: Xtest[i, :]})),nn_index)
# 最近邻分类标签与真实标签比较
if i%50==0:
print("Test", i, "Prediction:", np.argmax(Ytrain[nn_index]),"True Class:", np.argmax(Ytest[i]))# argmax最大值的下标
# 计算精确度
if np.argmax(Ytrain[nn_index]) == np.argmax(Ytest[i]):
accuracy += 1./len(Xtest)
print("Accuracy:", accuracy)
tensorflow实现KNN对文理分科的分类
模拟数据下载
导入数据
import pandas as pd
df = pd.read_csv("data/cjb.csv")
划分数据集
train_set = np.random.choice(len(df), 500, replace=False)
Xtrain = np.array(df.iloc[train_set,3:12])
Ytrain = np.array(df.iloc[train_set,[12]])
Xtest = np.array(df.iloc[-train_set,3:12])
Ytest = np.array(df.iloc[-train_set,[12]])
创建tensorflow结构
# 输入占位符
xtr = tf.placeholder("float", [None, 9]) # 不规定有多少sample,每个sample有9个属性
xte = tf.placeholder("float", [9])
# 计算L1距离
distance = tf.reduce_sum(tf.abs(tf.add(xtr, tf.negative(xte))), reduction_indices=1)
# 获取最小距离的索引
pred = tf.arg_min(distance, 0) # np.argmin(sess.run(distance, feed_dict={xtr: Xtrain, xte: Xtest[i, :]}))
测试模型
# 初始化变量
init = tf.global_variables_initializer()
#分类精确度
accuracy = 0.
# 运行会话,训练模型
with tf.Session() as sess:
# 运行初始化
sess.run(init)
# 遍历测试数据
for i in range(len(Xtest)):
# 获取当前样本的最近邻索引
nn_index = sess.run(pred, feed_dict={xtr: Xtrain, xte: Xtest[i, :]}) #向占位符传入训练数据
if i%50==0:
print("Test", i, "Prediction:", Ytrain[nn_index],"True Class:", Ytest[i])
# 计算精确度
if Ytrain[nn_index] == Ytest[i]:
accuracy += 1./len(Xtest)
print("Accuracy:", accuracy)
R语言实现KNN对文理分科的分类
导入数据划分测试集和训练集
library("tidyverse")
library('kknn')
cjb <- read.csv("data/cjb.csv")
cjb1 <- cjb %>%
select(4:13) %>%
mutate(wlfk = factor(wlfk))
train_set_idx <- sample(nrow(cjb), 0.7 * nrow(cjb))
test_set_idx <- (1:nrow(cjb))[-train_set_idx]
建立模型
imodel <- kknn(wlfk~., train = cjb[train_set_idx,], test = cjb[train_set_idx,])
查看测试集合预测结果
predicted_train <- imodel$fit
模型评估
Metrics::ce(cjb$wlfk[train_set_idx], predicted_train)