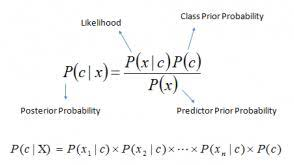
贝叶斯(Bayesian)是一种统计推断方法,其基本思想是利用已知的先验知识和观测数据来推导出未知参数的后验概率分布。贝叶斯方法在很多领域都有应用,例如机器学习、自然语言处理、信号处理等。
朴素贝叶斯(Naive Bayes)是贝叶斯方法中的一种应用,它是一种简单但非常有效的分类算法。朴素贝叶斯算法的基本假设是所有特征之间相互独立,因此可以通过各个特征的先验概率和条件概率来计算后验概率,从而进行分类。
因此,贝叶斯是一种推断方法,而朴素贝叶斯是一种分类算法。另外,朴素贝叶斯还有一个显著的特点是对于高维数据,其分类效果通常会比其他算法更好。
假设我们有一个文本分类问题,我们想要将一些电子邮件分类为垃圾邮件和非垃圾邮件。贝叶斯方法和朴素贝叶斯算法可以用来解决这个问题。
贝叶斯方法可以通过统计学方法来计算类别的后验概率。假设我们有两个类别,分别为“垃圾邮件”和“非垃圾邮件”,并且我们有一些先验知识,例如“垃圾邮件”的概率为10%,“非垃圾邮件”的概率为90%。对于一个新的电子邮件,我们可以计算出它属于“垃圾邮件”和“非垃圾邮件”的后验概率,并选择概率较大的类别作为它的分类结果。
而朴素贝叶斯算法则是一种特殊的贝叶斯方法,它假设所有特征之间相互独立。在文本分类问题中,我们可以将每个单词作为一个特征,并计算每个单词在“垃圾邮件”和“非垃圾邮件”中出现的概率。然后,对于一个新的电子邮件,我们可以计算它属于“垃圾邮件”和“非垃圾邮件”的概率,其中每个单词的概率可以通过先前计算得到的概率来计算。最后,我们选择概率较大的类别作为它的分类结果。
因此,贝叶斯方法是一种统计推断方法,可以用于计算类别的后验概率,而朴素贝叶斯算法则是一种基于贝叶斯方法的分类算法,它假设所有特征之间相互独立,并可以用于文本分类等问题。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 定义朴素贝叶斯分类器类
class NaiveBayesClassifier:
def __init__(self):
self.p_class = None
self.feature_counts = None
# 训练模型
def fit(self, X, y):
num_samples, num_features = X.shape
# 计算每个类别的先验概率
self.p_class = np.bincount(y) / num_samples
# 统计每个类别下每个特征出现的次数,并将次数转换为概率
self.feature_counts = np.zeros((2, num_features, 2))
for c in range(2):
X_c = X[y == c]
self.feature_counts[c, :, 0] = (X_c == 0).sum(axis=0)
self.feature_counts[c, :, 1] = (X_c == 1).sum(axis=0)
# 对测试集进行预测
def predict(self, X):
num_samples, num_features = X.shape
y_pred = np.zeros(num_samples)
for i in range(num_samples):
p_class_given_feature = self.p_class.copy()
for c in range(2):
for f in range(num_features):
p = self.feature_counts[c, f, X[i, f]]
# 计算后验概率
p_class_given_feature[c] *= p
# 找到后验概率最大的类别
y_pred[i] = np.argmax(p_class_given_feature)
return y_pred
# 生成人造数据集
np.random.seed(42)
X = np.random.randint(0, 2, size=(1000, 5))
y = np.random.randint(0, 2, size=1000)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型并预测
clf = NaiveBayesClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)