
加载数据
library(tidyverse)
cjb <- read.csv("/home/wy/Downloads/cjb.csv",
header = TRUE,
stringsAsFactors = FALSE,
fileEncoding = "UTF-8")
绘制茎叶图
cjb %>%
filter(bj == '1101') %>%
select(sx) %>%
as_vector() %>%
stem()
5 | 5799
6 | 0014
6 | 55789
7 | 000011122334444
7 | 788899
8 | 111222334444
8 | 589
9 | 224
绘制直方图
sx_hist_result = hist(cjb$sx,plot = FALSE)
typeof(sx_hist_result)
names(sx_hist_result)
# 使用ggplot绘制与hist相同的直方图
ggplot(data = cjb,mapping = aes(sx))+
geom_histogram(
breaks = sx_hist_result$breaks,
color = "darkgray",
fill = "white"
)+
stat_bin(
breaks = sx_hist_result$breaks,
geom = "text",
aes(label = ..count..)
)+
coord_flip()
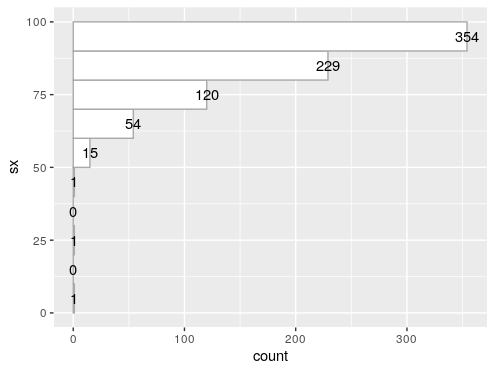
图片alt
绘制概率密度曲线
ggplot(data = cjb,mapping = aes(sx))+
geom_histogram(
breaks = sx_hist_result$breaks,
color = "darkgray",
fill = "white",
aes(y = ..density.. )
)+
geom_density(color = 'blue')

图片alt
绘制小提琴图
ggplot(cjb,aes(x=factor(0),y=sx))+
geom_violin(fill="orange",alpha=0.2)+
coord_flip()

图片alt
绘制箱线图
图片alt
cjb %>%
ggplot(aes(x=factor(0),y=sx))+
geom_boxplot(
width=0.25,
fill = "#E69F00",
outlier.colour = "red",
outlier.shape = 1,
outlier.size = .2
)+
geom_rug(position = "jitter",
size=0.1,
sides = "l")+
coord_flip()

图片alt
boxplot.stats(cjb$sx)
# $stats 下边界 一分位距 中位数 三分位距 上边界
# [1] 60 81 89 95 100
# $n 数据记录数
# [1] 775
# $conf
# [1] 88.20543 89.79457
# $out 异常点
# [1] 55 59 57 59 58 51 56 55 59 26 58 46 0 59 59
绘制小提琴图+箱线图
cjb %>%
ggplot(aes(x=factor(0),y=sx)) +
geom_violin(fill="#56B4E9",width=0.75) +
geom_boxplot(
width=0.25,
fill = "#E69F00",
outlier.colour = "red",
outlier.shape = 1,
outlier.size = 2
)+
geom_rug(
position = "jitter",
size=0.1,
sides = "l"
)+
coord_flip()
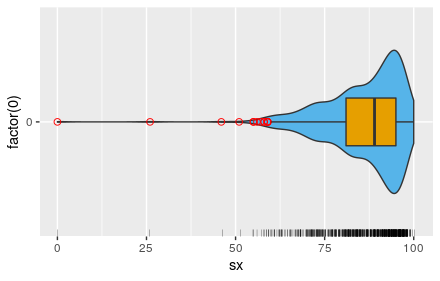
图片alt
集中趋势统计
cjb %>%
group_by(wlfk) %>% # 按文理分科分组统计
summarise(
count = n(), # 各组人数
sx_median = median(sx), # 中位数
sx_mean = mean(sx) # 均值
)
# A tibble: 2 x 4
# wlfk count sx_median sx_mean
# <chr> <int> <dbl> <dbl>
# 1 文科 394 84 82.7
# 2 理科 381 93 89.5
分散程度
cjb %>%
group_by(wlfk) %>% # 按文理分科分组统计
summarise(
sx_max = max(sx), # 最大值
sx_min = min(sx), # 最小值
sx_range = max(sx) - min(sx) # 极差
)
# A tibble: 2 x 4
# wlfk sx_max sx_min sx_range
# <chr> <int> <int> <int>
# 1 文科 100 26 74
# 2 理科 100 0 100
cjb %>%
group_by(wlfk) %>% # 按文理分科分组统计
summarise(
sx_O3 = quantile(sx,3/4), # 第三分位数
sx_min = quantile(sx,1/4), # 第一分位数
sx_iqr = IQR(sx) # 四分位距
)
# A tibble: 2 x 4
# wlfk sx_O3 sx_min sx_iqr
# <chr> <dbl> <dbl> <dbl>
# 1 文科 92 75 17
# 2 理科 96 86 10
apply的使用
round(apply(cjb[,4:12], 2, function(x){
c(
mean = mean(x),
median = median(x),
range = diff(range(x)),
IQR = IQR(x)
)
}))
# yw sx wy zz ls dl wl hx sw
# mean 87 86 87 92 89 93 81 92 86
# median 88 89 88 93 90 94 83 94 88
# range 96 100 99 100 100 100 100 100 100
# IQR 6 14 8 5 10 6 17 10 12