图片alt
code
dataset = load_dataset(source='upload')
results['pca'] = analyze(dataset=dataset, tool='pca', nr_genes=2500, normalization='logCPM', z_score=True, plot_type='interactive')
results['clustergrammer'] = analyze(dataset=dataset, tool='clustergrammer', nr_genes=2500, normalization='logCPM', z_score=True)
script_dirs = [os.path.join(os.path.dirname(os.path.realpath(__file__)), x) for x in ['core_scripts/*', 'analysis_tools/*']]
for script_dir in script_dirs:
for script_path in glob.glob(script_dir):
sys.path.append(script_path)
exec('import '+os.path.basename(script_path))
exec('import signature as sig')
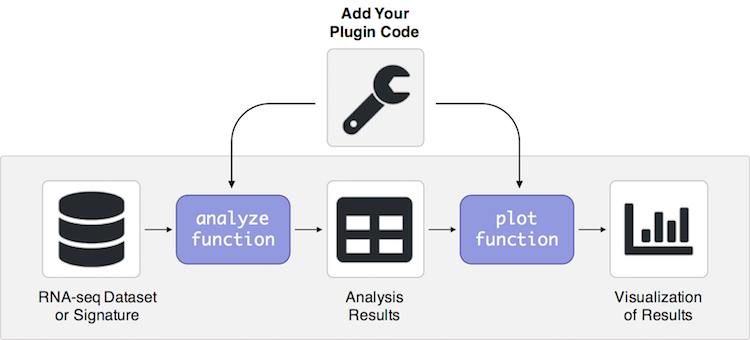
# Analyze
def analyze(tool, **kwargs):
# Normalize, if specified
normalization_method = kwargs.get('normalization')
if normalization_method and normalization_method not in kwargs['dataset'].keys():
kwargs['dataset'][normalization_method] = normalize_dataset(method = normalization_method, dataset=kwargs['dataset'])
return {'results': eval(tool).run(**kwargs), 'tool': tool}
# Plot
def plot(results, **kwargs):
return eval(results['tool']).plot(results['results'], plot_counter=plot_counter, **kwargs)