logistic
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import datasets
#导入数据
iris = datasets.load_iris()
#区分数据的自变量和因变量
iris_X = iris.data
iris_Y = iris.target
#将数据分成训练集和测试集,比例为:80%和20%
iris_train_X , iris_test_X, iris_train_Y ,iris_test_Y = train_test_split(
iris_X, iris_Y, test_size=0.2,random_state=0)
#训练逻辑回归模型
log_reg = LogisticRegression() #此处这个函数中有很多参数可供选择
log_reg.fit(iris_train_X, iris_train_Y)
#预测
predict = log_reg.predict(iris_test_X)
accuracy = log_reg.score(iris_test_X,iris_test_Y)
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
X, y = load_boston(return_X_y=True)
print(X.shape)
model = LinearRegression()
model.fit(X, y)
print(model.predict(X[:4,:]))
print(y[:4])
print(model.coef_)
print(model.intercept_)
print(model.get_params())
print(model.score(X, y)) # R^2 cofficient of determination
from sklearn.datasets import make_regression
import matplotlib.pyplot as plt
X,y = make_regression(n_samples=100, n_features=1, n_targets=1, noise=10)
plt.scatter(X,y)
from sklearn import preprocessing
import numpy as np
a = np.array([[10,2.7,3.6],
[-100,5,5],
[120,20,40]], dtype=np.float64)
print(a)
print(preprocessing.scale(a))
from sklearn import preprocessing
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
X,y = make_classification(n_samples=300, n_features=2, n_redundant=0, n_informative=2,
random_state=22, n_clusters_per_class=1, scale=100)
print(X.shape)
plt.scatter(X[:,0], X[:,1],c=y)
X_ = preprocessing.scale(X)
X_train,X_test,y_train,y_test = train_test_split(X_,y, test_size=.3)
clf =SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
## no scale
X_train,X_test,y_train,y_test = train_test_split(X,y, test_size=.3)
clf =SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
X,y =load_iris(return_X_y=True)
X_train,X_test,y_train,y_test = train_test_split(X,y, random_state=4)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train,y_train)
print(knn.score(X_test, y_test))
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
X,y =load_iris(return_X_y=True)
knn = KNeighborsClassifier(n_neighbors=5)
score = cross_val_score(knn, X, y, cv=5, scoring="accuracy")
print(score)
print(score.mean())
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
X,y =load_iris(return_X_y=True)
k_range = range(1,31)
k_score = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, X, y, cv=5, scoring="accuracy")
k_score.append(score.mean())
plt.plot(k_range, k_score)
plt.xlabel("Value of K for KNN")
plt.ylabel("Cross-Validated Accuracy")
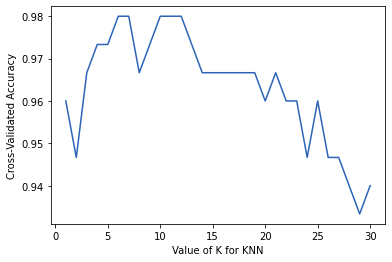
图片alt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
X,y =load_iris(return_X_y=True)
k_range = range(1,31)
k_score = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
loss = -cross_val_score(knn, X, y, cv=10, scoring="neg_mean_squared_error")
k_score.append(loss.mean())
plt.plot(k_range, k_score)
plt.xlabel("Value of K for KNN")
plt.ylabel("Cross-Validated Accuracy")
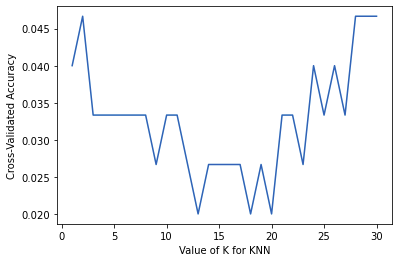
图片alt
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
X,y = load_digits(return_X_y=True)
train_sizes,train_loss,test_loss = learning_curve(SVC(gamma=0.001), X, y, cv=10,
scoring="neg_mean_squared_error",
train_sizes=[0.1,0.25,0.5,0.75,1])
train_loss_mean = -np.mean(train_loss,axis=1)
print(train_loss_mean)
test_loss_mean = -np.mean(test_loss,axis=1)
plt.plot(train_sizes,train_loss_mean,'o-',color="r",label="Training")
plt.plot(train_sizes,test_loss_mean,"o-",color="g",label="Cross-validation")
plt.legend(loc="best")
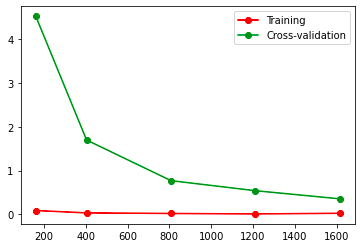
图片alt
Overfitting
测试数据集的loss不能下降
train_sizes,train_loss,test_loss = learning_curve(SVC(gamma=0.1), X, y, cv=10,
scoring="neg_mean_squared_error",
train_sizes=[0.1,0.25,0.5,0.75,1])
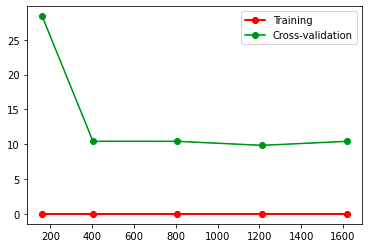
图片alt
solve Overfitting
没有Overfitting, 可以减少误差
from sklearn.model_selection import validation_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
X,y = load_digits(return_X_y=True)
param_range = np.logspace(-6, -2.3,5)
train_loss,test_loss = validation_curve(SVC(), X, y,
param_name="gamma",
param_range=param_range, cv=10,
scoring="neg_mean_squared_error")
train_loss_mean = -np.mean(train_loss,axis=1)
test_loss_mean = -np.mean(test_loss,axis=1)
plt.plot(param_range,train_loss_mean,'o-',color="r",label="Training")
plt.plot(param_range,test_loss_mean,"o-",color="g",label="Cross-validation")
plt.legend(loc="best")
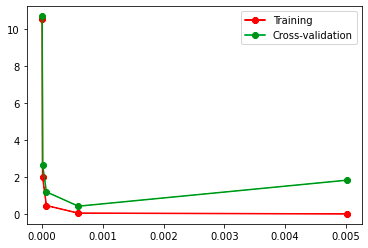
图片alt
save model
from sklearn import svm
from sklearn import datasets
import pickle
import joblib
X,y = datasets.load_iris(return_X_y=True)
clf = svm.SVC()
clf.fit(X,y)
with open("clf.pickle","wb") as f:
pickle.dump(clf, f)
with open("clf.pickle","rb") as f:
clf2 = pickle.load(f)
print(clf2.predict(X[0:1]))
joblib.dump(clf,"clf.pkl")
clf3 = joblib.load("clf.pkl")
print(clf3.predict(X[0:1]))